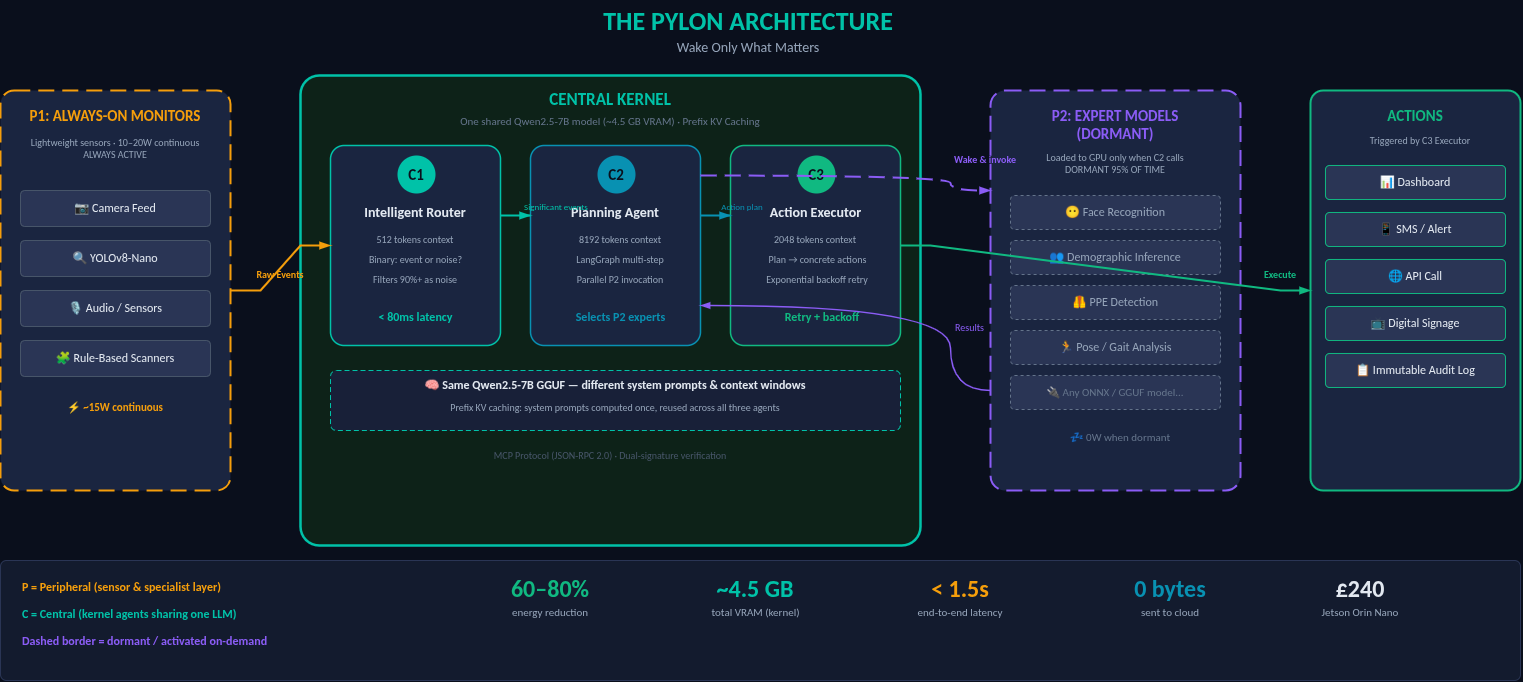



How Selective Activation Cuts Edge AI Energy by 80%
Most edge AI systems waste 70–90% of compute on always-on models. Learn how Pylon's selective activation cuts energy use by 80% for privacy-first Physical AI at the edge.
#technical#energy#architecture